
Why Your Office Needs a Laugh Detector

Play goes hand in hand with innovation. I learned this from Brendan Boyle, director of IDEO's Play Lab, who says that if you measure the amount of laughter in a project space, the teams who chuckle most are also the most successful. As a data scientist, this idea got my gears turning: What if I could use machine learning to build a laugh-detecting algorithm?
Prototyping is a great way to explore how emerging technologies will play a role in our connected future. But instead of focusing on how we will teach our machines to sense human behavior, I’m interested in designing what we will do with the information our devices are learning. In a world filled with machines that learn and interact with us, it’s important that they are able to respond to all parts of our humanity—including the things that make us laugh.
I wanted to see what kind of laugh detection prototype I could build in a few weeks. Here’s how I did it:
1. Building the algorithm
To build the laugh-detecting algorithm, I knew that I wanted to use deep learning, so I turned to Keras, a programming library which makes creating neural networks fast and simple. To train the laugh detector, I needed to use sequences of audio as the input and predict whether or not laughter would result as the output. Fortunately, I found Audioset, a collection of over two million 10-second audio clips with labels from over 6,000 categories. Using a subset of the Audioset collection that is half laughter and half speech, I was able to get a laughter detection model running with 87 percent accuracy within a few days.
After creating a training dataset, I got started on the machine learning challenge. The Audioset data does not contain the extracted raw audio, only a 128-length feature vector for each second of input, which is created using a convolutional network operating on the raw audio spectrogram. These feature vectors will be the input for the machine learning algorithm, and the output will be a binary label of whether the input contained laughter. Since I am working with a relatively large dataset, I wanted to use some deep learning methods, so I turned to keras, an API that makes creating and training neural networks extremely simple, while still leveraging the computational efficiency of optimized tensor computation libraries like TensorFlow and Theano.

Since the model input is sequential, I wanted to try a recurrent neural network first. I started with a single layer LSTM model that quickly converged to 87% accuracy. Learning from the code in a very similar project, I found that applying batch normalization to the LSTM input was very important for getting the model to converge. One of the headaches of deep learning is that seemingly trivial details like this can have a large impact on convergence. I was happy with the performance of my first LSTM model, but I decided to try out a couple more options before moving on. I tried a 3-layer LSTM (because if one layer is good, three must be better), then I tried a simple logistic regression model to see if the fancy RNN architecture made a difference. The models performed with 88% and 86% accuracy, respectively, which showed me that, in this case, more layers did not equate to more power.
Ultimately, I ended up choosing the single layer LSTM, even though it was larger than the logistic regression model, because it was able to handle variable length input. The training data was all sequences that were 10 seconds long, but I wanted the laughter detector to be able to respond quicker than that. While the logistic regression could only operate on input that was the same length as the training data, the LSTM model can still operate on any input length, as long as it is split into one-second chunks.
To take the trained model and run it as a live laugh detector, I put together a python script that pulled together a few different steps. First, the audio is captured from the microphone using pyaudio and chunked into three-second clips. (The length of these clips is an adjustable parameter.) The raw audio is then fed into the pre-trained vggish network and converted to a sequence of feature vectors with the same parameters I used for creating the Audioset training data. The sequence is then fed into the trained LSTM model, and the laughter prediction score is returned and written to a timestamped .csv file. By default, the raw audio is then discarded, and only the score is saved. That way, there are no concerns about storing or transmitting anyone’s private conversations. By running the audio capture and processing in separate threads, I was able to run this continuously without any lag on my laptop.
2. Designing the experience
Once I had the ability to measure laughter, I had to tackle the real design challenge: How do we implement the laugh detector in project spaces without making it seem obnoxious or creepy?
I enlisted the help of a few smart colleagues to approach the challenge from multiple angles: a software designer experienced in designing for play, an environments designer to explore how the detector would show up in a project space, and a communication designer who’s written on the science of laughter.
We had a brainstorm around what we might be able to do with a laughter detector, and the ideas poured in. Perhaps we could use laughter as a weekly indicator of morale (similar to Bhutan’s gross national happiness), or host a competition between project teams for who laughed the most? If we could determine when people are laughing, maybe we could figure out why they are laughing, too. We could determine when laughter is genuine or just polite, which jokes are the funniest, or even measure who is laughed at the most.
Some of the more wild ideas included a gif of an IDEO Chicago director Jon Wettersten (below) who laughs along with us, or an alert that would play videos of clowns if we went too long without laughing.
Ultimately, we wanted to select ideas that would give teams insight into their laughter, but not be too intrusive or prescriptive.
Information systems shouldn’t overwhelm users—particularly when that information concerns people’s moods. There are times when it’s appropriate to not be laughing; you don’t want your smartwatch telling you to laugh more during your grandma’s funeral. And if we were to build a device that listens for laughter, we'd need to make sure that we communicate and maintain people’s expectations of privacy.
With all this in mind, we narrowed it down to two concepts that we would take forward into the prototyping phase.
3. Hatching prototypes
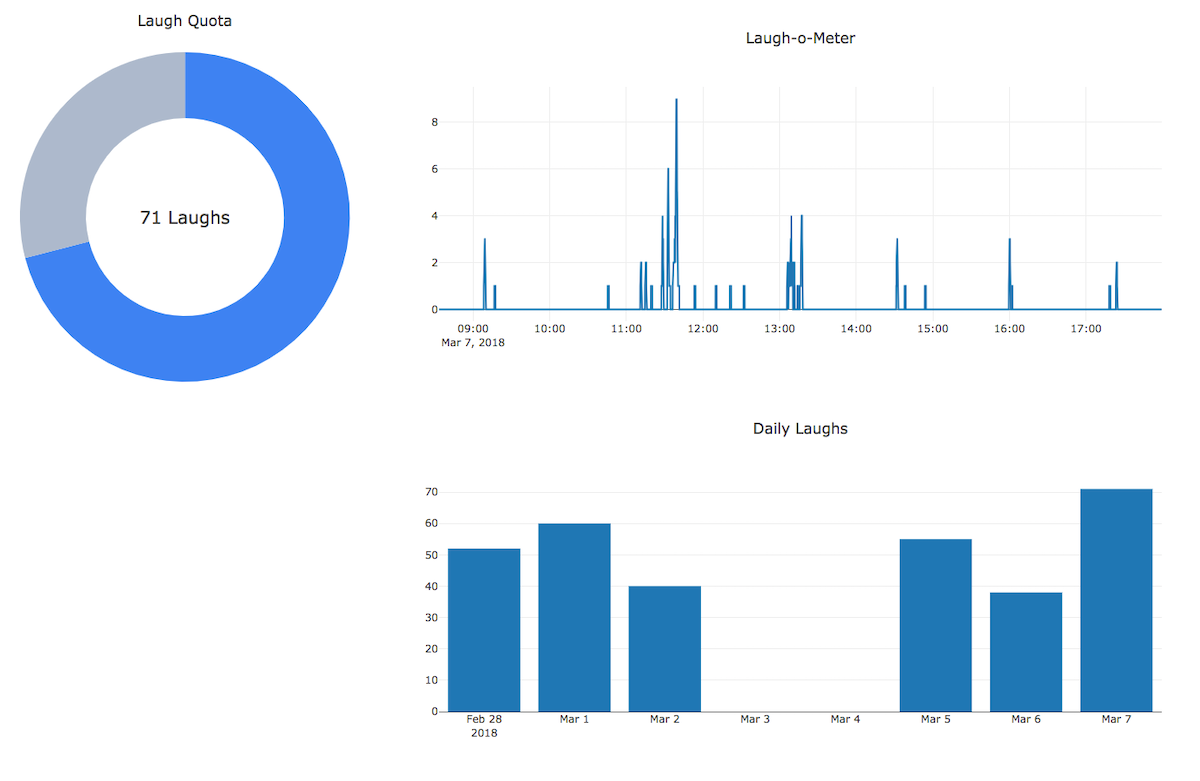
The first thing we made was a simple information dashboard built in Dash. We referred to this design as a “FitBit for laughter,” as it was meant to help teams set goals and measure their progress towards those goals.
This raised the the question, what if you could track your emotional health in the same way that you tracked your physical health? What kind of goals would you set? What would your “laughter workout” look like?
To start, we measured laughs by time of day over a period of 24 hours, laughs per day over the past week, and how close teams are to achieving a daily “laugh quota.”
The second prototype used the output of the laugh detector to control the color and intensity of a Hue lightbulb. When there is a lot of laughter in a room, the light glows a bright yellow to mirror the warmth that laughter brings to a space. When there is less laughter, it transitions to a dim blue to help teams stay calm and focused. In this way, the environment responds to the activities and emotion of its inhabitants.
What if the smart systems we create could react not only to a user’s presence or interaction, but adapt to the user’s mood? How might we design smart systems or spaces that are emotionally responsive?
4. User testing
We wanted to see how people would react to the laugh-bulb, so we got a few colleagues to sit down and test it out. The original plan was to play funny videos to stimulate laughter, but as soon as people sat down, they started joking so much, the videos were unnecessary.
Laughter is a reinforcing behavior; when you laugh, the people around you laugh too, creating a virtuous cycle that can leave you laughing until you’re sore. Seeing the light grow brighter as the room fills with laughter adds energy to that cycle. The group that came in to test the laugh-bulb ended up laughing so much that you could hear them throughout the studio.
WATCH: Testing the laugh-bulb prototype.
Next up, I’d love to put these prototypes in front of more people to see whether quantifying laughter can affect their mood. And I'm left wondering, which emotional or mental health signals could be measured and recorded next?
As more aspects of our lives are recorded, we are going to be able to quantify and improve our lives in ways we can’t yet imagine. Let’s design these systems not just to make us smarter, but to make us more joyful, too.





Subscribe to the IDEO newsletter
.jpg)
